La API estándar de Java provee de mecanismos para la localización de recursos (mensajes de texto, URLs a imágenes u otros recursos…) mediante la utilización de la clase ResourceBundle. La forma más conocida y habitual de usarlos es a través de ficheros de propiedades, en los que se especifican los recursos a utilizar para cada localización en forma de clave – valor, pero existen otras posibilidades, como por ejemplo la utilización de clases java.
Todas las entradas de: Antonio Archilla
OCP7 14 – Patrones de Diseño en Java (Singleton, Factory y Dao)
Los patrones de diseño consisten en soluciones reutilizables a problemas comunes en el desarrollo de software.
Estas soluciones se encuentran ampliamente documentadas y pretenden formalizar el vocabulario usado para hablar del diseño de software.
Patrón Singleton
Persigue el objetivo de mejorar el rendimiento de una aplicación impidiendo la creación de varias instancias de una clase.
Para la implementación de este patrón se utilizará una clase con una variable de referencia estática:
public class SingletonClass {
private static final SingletonClass instance = new SingletonClass();
private SingletonClass() {}
public static SingletonClass getInstance() {
return instance;
}
}
la cual contendrá la única instancia de la clase. También se marca esta variable como final para que no pueda ser reasignada una instancia diferente.
Se añade un constructor privado private SingletonClass() {} de modo que sólo se permita el acceso a él des de la misma clase impidiendo cualquier intento de instanciarla de nuevo.
Por último se añade un método público y estático el cuál podrá acceder al campo estático y devolver su valor.
public static SingletonClass getInstance() {
return instance;
}
Mediante este método se puede recuperar la instacia creada cuándo sea requerido el objeto que implementa la clase Singleton.
Patrón Dao (Data-Acces-Object)
Es un patrón de diseño ampliamente conocido que separa la lógica de negocio de la persistencia de los datos.Permite una mayor facilidad de implementación del código y una mayor sencillez de mantenimiento del mismo. A su vez es más escalable y ampliable.
Patrón Factory
Patrón de diseño que separa la clase que crea los objetos de la jerarquía de los objetos a instanciar dentro del espacio de memoria
Los objetivos intenta conseguir consisten en:
-Una centralización de la creación de los objetos en memoria.
–Escalabilidad del Sistema.
–Abstracción del usuario sobre la instancia a crear.
Un ejemplo de implementación del patrón Factoria es el siguiente:
EmployeeDAOFactory factory = new EmployeeDAOFactory(); EmployeeDAOFactory dao = factory.createEmployeeDAOFactory();
Mediante este patrón de diseño Factory se impide que una aplicación se vincule a una aplicación específica implementadora del Patrón Dao.
Se debe evitar la duplicación de código siempre que se pueda y refactorizar al máximo posible sin poner en riesgo la funcionalidad de la aplicación y dejándola intacta. La Factoría permite obtener estos resultados de una forma eficiente.
Patrón Cadena de Responsabilidad
El patrón de diseño Cadena de Responsabilidad (Chain of Responsability) es un patrón de tipo «comportamiento», es decir, que establece protocolos de interacción entre clases y objetos emisores y receptores de los mensajes a procesar. Se utiliza para desacoplar las diferentes implementaciones de un algoritmo de su uso final, ya que el emisor del mensaje no tiene porqué conocer el componente que finalmente procesará el mensaje.
- Se forma una lista encadenada con todos los posibles receptores del mensaje, de forma que cada uno de ellos dispone de un enlace al siguiente, si se quiere, ordenados pueden ordenarse por prioridad de forma que en caso de que varios de ellos sean capaces de procesar un mismo mensaje, prevalezca el que tenga una prioridad mas alta según criterios funcionales.
- El emisor del mensaje, sólo ha de tener acceso al primero de los receptores. Será a este al que se le hará la llamada inicial y quien proporcionará el resultado al emisor.
- Cada uno de los receptores, evaluará el mensaje proporcionado por el emisor y decidirá si es capaz de procesarlo y proporcionar un resultado. En caso afirmativo, se acabará la cadena de llamadas a posteriores receptores y se retornará. Esto hará que el resultado pase por todos los receptores ejecutados anteriormente hasta devolvérselo al emisor. En caso que el receptor actual no sea capaz de evaluar el mensaje, delegará en el siguiente receptor en la cadena esperando el resultado que le proporcione, sea él o no el que finalmente se haga cargo de proporcionárselo.
El siguiente diagrama de secuencia ilustra los puntos detallados con anterioridad:
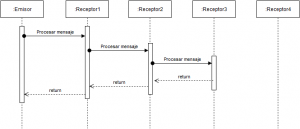
En él se puede observar una situación en la que se dispone de un emisor y 4 receptores capaces de procesar diferentes mensajes. El emisor hace la llamada al primer de los receptores para que le proporcione el resultado. Éste, al evaluarlo, ve que no es capaz de procesarlo y delega en el segundo de los receptores y así sucesivamente hasta llegar al tercero de ellos, que si es capaz de hacerlo y proporciona un resultado, haciendo innecesaria la propagación del mensaje al cuarto de ellos. El resultado se propaga por los receptores 1 y 2 hasta llegar al emisor de forma transparente.
Ejemplo de implementación utilizando Spring:
http://bitsmi.com/2015/12/patron-cadena-de-responsabilidad-con-spring-2/
http://bitsmi.com/2015/12/patron-cadena-de-responsabilidad-con-spring-2/
Gestión de dependencias Maven mediante la librería Aether
Aether es una librería Java que permite integrar en cualquier aplicación Java el mecanismo de resolución de dependencias de Maven. Se trata de una forma mucho más simple de hacerlo que integrar la distribución completa de Maven o incrustar Plexus dentro de la aplicación.
La API de Aether provee funcionalidades para:
- Definir y gestionar de un repositorio local de artefactos.
- Recuperar artefactos desde múltiples repositorios remotos para su consumo local.
- Publicar artefactos locales en múltiples repositorios remotos.
- Resolver las dependencias transitivas de los artefactos.
- Inspeccionar el grafo de dependencias de un artefacto.
En este post se exponen ejemplos concretos de implementaciones para las funcionalidades anteriormente mencionadas.
Seguir leyendo Gestión de dependencias Maven mediante la librería Aether
Orden de ejecución de los métodos de un test case de JUnit4
Deprecated
Aunque quizá JUnit4 sea el framework de testing más extendido en el ecosistema Java, adolece de ciertas limitaciones «de fábrica» que según como se mire son difíciles de explicar. Una de ellas para mi gusto es la dificultad de poder marcar el orden de ejecución de los métodos de una clase de test de forma sencilla. Entiendo que mirándolo de una forma purista cada uno de los métodos de un test case debe ser independiente y su ejecución no se debería ver afectada por el resto, pero en determinados casos es de mucha ayuda poder marcar el orden de ejecución, como por ejemplo poder probar la conexión a una fuente de datos antes de obtener los datos.
En este articulo se pretende exponer diferentes alternativas para dar respuesta a este caso de uso.
Seguir leyendo Orden de ejecución de los métodos de un test case de JUnit4
Error NullPointerException al evaluar una expresión ternaria
Descripción de error
Se produce un error de tipo NullPointerException al evaluar una expresión ternaria donde se mezclan valores de tipo primitivo (int, long, double…) con sus correspondientes tipos Wrapper (Integer, Long, Double) si el valor de resultante de la expresión es null.
Cuando la expresión condicional evalua y se asigna un valor no nulo, en este caso el segundo operando de la expresión, la operación funciona correctamente:
long val1 = 1;
Long valor2 = val1==1 ? val1 : (Long)null;
System.out.println("VALOR2 is null -> " + (valor2 != null));
VALOR2 is null -> true
En cambio, cuando se evalúa la condición y el valor resultante es null, tercer operando en el ejemplo, aunque este último se trate como un tipo objeto, se produce un error:
long val1 = 2;
Long valor2 = val1==1 ? val1 : (Long)null;
System.out.println("VALOR2 is null -> " + (valor2 != null));
Exception in thread "main" java.lang.NullPointerException
Solución propuesta
El error se produce porque en las expresiones ternarias de este tipo, el compilador escoge como tipo de retorno el valor primitivo, en el caso de los ejemplos anteriores el tipo long en lugar del tipo wrapper Long. Por esta razón, aunque se especifique una conversión explicita al tipo adecuado cuando se utiliza un valor nulo, siempre se producirá un error si ese es el resultado de la operación ya que el tipo primitivo no admite este tipo de valores.
La solución simple a este error es trasformar en todos los casos el valor resultante a un tipo wrapper. En el ejemplo, el segundo miembro de la operación es transformado a Long mediante el método valueOf para que todos los operandos sean de este tipo, que si admite valores nulos. El compilador escogerá este tipo para el resultado de la operación ya que es el único presente en las 2 alternativas, tanto si se cumple la condición como si no.
long val1 = 2;
Long valor2 = val1==1 ? Long.valueOf(val1) : (Long)null;
System.out.println("VALOR2 is null -> " + (valor2 != null));
VALOR2 is null -> false
Referencias
- Definición del operador ternario en la especificación del lenguaje Java (JLS): http://docs.oracle.com/javase/specs/jls/se8/html/jls-15.html#jls-15.25
Error al tratar un dato de tipo CLOB con Hibernate en una base de datos PostgreSQL
Descripción de error
Se produce un error al recuperar datos de tipo LOB de una entidad a través de la capa de persistencia basada en JPA + Hibernate si la base de datos subyacente es PostgreSQL. Se produce un error de tipo:
org.postgresql.util.PSQLException: Bad value for type long
La configuración de los campos de una entidad incialmente es la siguiente:
@Basic(fetch=FetchType.LAZY) @Lob protected String stringLargeValue;
Entorno
- JDK: 1.6. Es posible que ocurra también en versiones posteriores (No probado)
- Framework de persistencia: JPA con Hibernate 3.6. No se ha probado con la versión 4 ni posteriores.
- Base de datos: PostgreSQL 9.2.4, Es posible que ocurra también en versiones posteriores (No probado)
Solución propuesta
Parece ser que hay una falta de entendimiento entre Hibernate 3.6 y el driver de PostgreSQL porque lo que uno entiende como dato (Hibernate) el otro lo entiende como el puntero de tipo long para acceder a este (PostgreSQL) por lo que al hacer la extracción de datos este intenta hacer una conversión y provoca el error. Una posible solución se basa en configurar la propiedad de tipo LOB de la entidad con la anotación @Type de la siguiente manera para indicarle a Hibernate como debe tratar el valor recuperado:
@Basic(fetch=FetchType.LAZY) @Lob @Type(type="org.hibernate.type.TextType") protected String stringLargeValue;
Patrón Cadena de Responsabilidad con Spring
El patrón de diseño Cadena de Responsabilidad (Chain of Responsability) es un patrón de tipo «comportamiento», es decir, que establece protocolos de interacción entre clases y objetos emisores y receptores de los mensajes a procesar. Es usado para desacoplar las diferentes implementaciones de un algoritmo de su uso final, ya que el emisor del mensaje no tiene porqué conocer el componente que finalmente procesará el mensaje.
Su funcionamiento básico es el siguiente:
- Se forma una lista encadenada con todos los posibles receptores del mensaje, de forma que cada uno de ellos tengo un enlace al siguiente, si se quiere, ordenados pueden ordenarse por prioridad de forma que en caso de que varios de ellos sean capaces de procesar un mismo mensaje, prevalezca el que tenga una prioridad mas alta según criterios funcionales.
- El emisor del mensaje, sólo ha de tener acceso al primero de los receptores. Será a este al que se le hará la llamada inicia y quien proporcionará el resultado al emisor.
- Cada uno de los receptores, evaluará el mensaje proporcionado por el emisor y decidirá si es capaz de procesarlo y proporcionar un resultado. En caso afirmativo, se acabará la cadena de llamadas a posteriores receptores y se retornará. Esto hará que el resultado pase por todos los receptores ejecutados anteriormente hasta devolvérselo al emisor. En caso que el receptor actual no sea capaz de evaluar el mensaje, delegará en el siguiente receptor en la cadena esperando el resultado que le proporcione, sea el o no el que finalmente se haga cargo de proporcionárselo.Todo lo explicado hasta ahora se puede resumir en el siguiente diagrama de secuencia:
En él se puede observar una situación en la que se dispone de un emisor y 4 receptores capaces de procesar diferentes mensajes. El emisor hace la llamada al primer de los receptores para que le proporcione el resultado. Éste, al evaluarlo, ve que no es capaz de procesarlo y delega en el segundo de los receptores y así sucesivamente hasta llegar al tercero de ellos, que si es capaz de hacerlo y proporciona un resultado, haciendo innecesaria la propagación del mensaje al cuarto de ellos. El resultado se propaga por los receptores 1 y 2 hasta llegar al emisor de forma transparente.
Un ejemplo de su uso muy simple seria el siguiente. Se quiere construir un sistema capaz de traducir palabras en diferentes idiomas al castellano. Utilizando este patrón de diseño, se dispondría de un componente capaz de procesar mensajes de un idioma concreto, uno en ingles y otro en alemán, por ejemplo. También sería posible que para un mismo idioma hubiera diferentes receptores para, por ejemplo, procesar mensajes de saludo. En este caso este receptor específico tendría que estar situado en posiciones anteriores de la cadena de receptores al otro mas genérico. El siguiente diagrama muestra el comportamiento descrito:
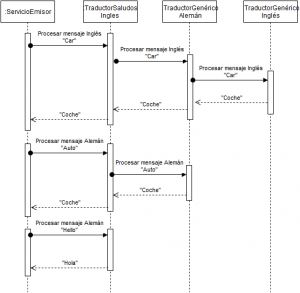
Implementación mediante Spring
A continuación se muestra una posible implementación del patrón utilizando el contenedor IOC Spring. La propuesta que se describe aquí dista un poco de la realizada en el texto anterior, aunque el concepto subyacente es el mismo: Delegar la responsabilidad de realizar una acción a componentes organizados en forma de lista priorizada en la que en caso que un integrante no sea capaz de realizar la acción, delega en el siguiente en la lista y así sucesivamente hasta que uno de ellos pueda hacerse cargo y proporcionar un resultado.
En este caso, en lugar de que cada uno de los componentes receptores sea responsable de llamar al siguiente en la cadena si no es capaz de procesar el mensaje y de proporcionar el resultado final al receptor anterior o el emisor si se trata del primero en la cadena de llamadas, se implementa un servicio centralizado de ejecución en el cual se registraran todos los receptores que intervendrán en la cadena. De esta forma, el componente emisor sólo tiene conocimiento de la existencia del servicio de ejecución y se permite el registro dinámico de nuevos componentes de forma más sencilla que en el caso de tener los receptores encadenados los unos con los otros.
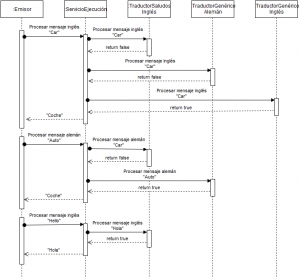
Para la implementación del ejemplo se han realizado los siguientes pasos:
- Se define la interfaz IChainExecutionElement que establecerá el contrato que todas las implementaciones del servicio de traducción deberán cumplir. En este caso, se define un método principal doChain que recibirá el mensaje de entrada a procesar y devolverá un booleano dependiendo de si ha podido procesarlo (true) o no (false). De esta manera el servicio de ejecución de la cadena de receptores sabe si debe propagar el mensaje al siguiente receptor.
public interface IChainExecutionElement
{
public boolean doChain(TranslationChainMessage action) throws Exception;
}
- Se define el formato del mensaje que se proporcionará desde el emisor a cada uno de los receptores encargados de realizar la traducción. En este caso, el mensaje estará formado inicialmente por la cadena de texto a traducir y el idioma en que se encuentra. También cuenta con los campos necesarios para que el receptor sea capaz de especificar el resultado obtenido, esto es, el texto traducido y un indicador de quien ha sido el componente responsable de la traducción, puesto aquí para poder ver cómo funciona el algoritmo implementado.
public class TranslationChainMessage
{
private String language;
private String message;
private String translation;
private String processorName;
. . .
}
- Se implementa un servicio encargado de ejecutar el algoritmo de ejecución de la cadena, que se llevará a cabo mediante un bucle que se encarga de llamar a todos los receptores de mensajes registrados pasándoles el mensaje recibido desde el emisor. La iteración finalizará cuando uno de los receptores sea capaz de procesar el mensaje y proporcionar un resultado. Este servicio permite el registro de los componentes receptores mediante el mecanismo de inyección de dependencias que proporciona Spring, de forma que todos los beans de Spring que cumplan el contrato definido por la interfaz IChainExecutionElement se registrarán automáticamente. También se permite la ordenación de los componentes según prioridad haciendo uso de la anotación @Order que proporciona Spring en los diferentes componentes receptores para definir esta prioridad y ordenando la lista en el método de inicialización (anotado con @PostConstruct) del servicio de ejecución una vez han sido inyectados todos.
@Service
public class ChainExecutionService
{
@Autowired
private List chain;
@PostConstruct
public void init()
{
Collections.sort(chain, AnnotationAwareOrderComparator.INSTANCE);
}
public void setChain(List chain)
{
this.chain = chain;
}
public void executeChain(TranslationChainMessage action) throws Exception
{
boolean breakLoop = false;
Iterator iterator = chain.iterator();
while(iterator.hasNext() && !breakLoop){
IChainExecutionElement delegate = iterator.next();
if(delegate.doChain(action)){
breakLoop = true;
}
}
if(!breakLoop){
// No se ha encontrado ninguna implementación para tratar el elemento
throw new Exception("No se ha encontrado ninguna implementación para tratar el elemento");
}
}
}
- Mediante el escaneo dinámico del classpath que proporciona Spring cómo método de configuración mediante la anotación @ComponentScan, se pueden añadir diferentes implementaciones del servicio de traducción sin necesidad de modificar el código principal de la aplicación. En este caso todas la implementaciones disponibles se encuentran bajo el package indicado en dicha anotación, que será explorada durante la inicialización de este en busca de definiciones de beans. Lo que hace este mecanismo realmente flexible es la posibilidad de incluir estos componentes en varios módulos diferentes, incluso ubicados en ficheros jar distintos, y utilizar el escaneo dinámico para recuperarlos todos para su utilización.
@Configuration
@ComponentScan({"snippets.ioc.spring.cor"})
public class ChainOfResponsabilityConfig
{
}
- A continuación se muestra un ejemplo de implementación de un componente de tipo receptor. Se puede ver la definición como componente de Spring mediante la anotación @Component, la inicialización del componente estableciendo qué palabras es capaz de traducir y el método doChain decide si es capaz de procesar el mensaje de entrada y de proporcionar un resultado si es el caso. También se puede observar como se indica al servicio ejecutor si ha sido capaz de procesar el mensaje devolviendo true o false.
@Component
public class EnglishMessageProcessor implements IChainExecutionElement
{
private Map translationMap;
@PostConstruct
private void setUp()
{
translationMap = ImmutableMap.builder()
.put("Hello", "Hola")
.put("Goodbye", "Adios")
.put("Car", "Coche")
.put("House", "Casa")
.build();
}
@Override
public boolean doChain(TranslationChainMessage action) throws Exception
{
// Sólo se procesará en caso que el idioma sea el esperado
// y se tenga la traducción para el mensaje recibido
if(!"en".equals(action.getLanguage())
|| !translationMap.containsKey(action.getMessage())){
return false;
}
action.setTranslation(translationMap.get(action.getMessage()));
action.setProcessorName("EnglishMessageProcessor");
return true;
}
}
En el repositorio adjunto en los links de interés, se pueden consultar la implementación del resto de componentes realizados para el ejemplo, todos con una estructura similar.
- Para probar la implementación de ejemplo realizada, se ha diseñado un test muy simple en el que se pasan diferentes palabras a traducir en inglés o alemán y se comprueba el resultado y quien ha sido el responsable de la traducción.
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes={ChainOfResponsabilityConfig.class})
public class ChainOfResponsabilityTestCase
{
@Autowired
private ChainExecutionService executionService;
@Test
public void translationTest() throws Exception
{
TranslationChainMessage message1 = new TranslationChainMessage();
message1.setLanguage("en");
message1.setMessage("Car");
executionService.executeChain(message1);
Assert.assertEquals("Coche", message1.getTranslation());
Assert.assertEquals("EnglishMessageProcessor", message1.getProcessorName());
TranslationChainMessage message2 = new TranslationChainMessage();
message2.setLanguage("de");
message2.setMessage("Auto");
executionService.executeChain(message2);
Assert.assertEquals("Coche", message2.getTranslation());
Assert.assertEquals("GermanMessageProcessor", message2.getProcessorName());
TranslationChainMessage message3 = new TranslationChainMessage();
message3.setLanguage("en");
message3.setMessage("Hello");
executionService.executeChain(message3);
Assert.assertEquals("Hola", message3.getTranslation());
Assert.assertEquals("EnglishGreetingsMessageProcessor", message3.getProcessorName());
}
}
Enlaces de interés
Todo el código desarrollado para este ejemplo se encuentra en el repositorio online BitBucket en la URL
OCP7 10 – E/S de archivos Java – Parte 3 – FileStore y WatchService
Clase FileStore
La clase FileStore es útil para proporcionar información de uso sobre el sistema de archivos como el total de disco utilizable y asignado.
Filesystem kbytes used available
System (C:) 209748988 72247420 137501568
Data (D:) 81847292 429488 81417804
En este enlace oficial de Oracle puede estudiarse la implementación de FileStore.
Interfaz WatchService
La implementación de la interfaz de WatchService representa un servicio de vigilancia que observa los cambios producidos en los objetos Path registrados.
Por ejemplo, una instancia de WatchService puede usarse para identificar cuándo fueron añadidos, borrados o modificados archivos en un directorio.
ENTRY_CREATE: D:testNew Text Document.txt
ENTRY_CREATE: D:testFoo.txt
ENTRY_MODIFY: D:testFoo.txt
ENTRY_MODIFY: D:testFoo.txt
ENTRY_DELETE: D:testFoo.txt
NOTA:
La implementación del mecanismo de observación del sistema de ficheros es dependiente de la plataforma de ejecución.
Por defecto, se intentan mapear los eventos que se observan a través del WatchService con los eventos nativos que el Sistema Operativo genera ante los cambios de ficheros. Esto hace que sea posible encontrarse diferentes tipos de eventos resultados de una misma acción.
En caso que no sea posible consumir los eventos nativos, la implementación en caso de error se encargará de polling consultar el estado de los elementos del sistema de ficheros indicado.
La contra partida de este mecanismo de fallback es que ante eventos muy seguidos, es posible que no se reciban todos los eventos generados si el tiempo entre muestra y muestra es superior al tiempo transcurrido entre los eventos.
En todo caso, la utilización de este servicio ha de tener en cuenta esta particularidad para no obtener resultados inesperados.
En este enlace oficial de Oracle puede estudiarse con más detalle el funcionamiento de la interfaz WatchService.
OCP7 10 – E/S de archivos Java – Parte 2 – Interfaz FileVisitor
Operaciones recursivas
La classe Files ofrece un método para recorrer el árbol de archivos en busca de operaciones recursivas, como de copia y de supresión.
Interfaz FileVisitor<T>
La interfaz FileVisitor<T> permite realizar el recorrido de un nodo raíz de forma recursiva. Puede encontrarse la implementación en la API del JDK 7 en el siguiente enlace.
Para poder llevar a cabo el recorrido recursivo mencionado con anterioridad se detallan los siguientes métodos, representando puntos clave del recorrido recursivo. Son métodos a los que se vaya llamando cada vez que se visita uno de los nodos del árbol:
- FileVisitResult preVisitDirectory(T dir, BasicFileAttributes attrs). Se invoca en un directorio antes de que se visiten las entradas del directorio.
- FileVisitResult visitFile(T file, BasicFileAttributes attrs). Se invoca cuándo se visita un archivo.
- FileVisitResult postVisitDirectory(T dir, IOException exc). Se invoca después que se hayan visitado todas las entradas un directorio y sus descendientes.
- FileVisitResult visitFileFailed(T dir, IOException exc). Se invoca cuándo un archivo no ha podido ser visitado.
El objeto FileVisitResult es el tipo de retorno para la interfaz FileVisitor. Contiene cuatro constantes que permiten procesar el archivo visitado e indicar que debe ocurrir en el próximo archivo (Enum FileVisitResult – para un mayor detalle se puede consultar directamente la API de JDK 7 en este enlace). Estas constantes representan las acciones que tomar tras alcanzar un nodo (antes o después):
- CONTINUE: Se debe continuar la visita del siguiente nodo en el árbol de directorios.
- SKIP_SIBLINGS: Señala que se debe continuar el recorrido sin visitar a los hermanos del archivo o directorio.
- SKIP_SUBTREE: Señala que se debe continuar el recorrido de los nodos sin visitar las entradas de este directorio.
- TERMINATE: Indica la finalización del proceso de visita.
A continuación se muestra un código Java que ilustra la utilización de los cuatro métodos definidos con anterioridad:
package recursiveoperations;
import java.io.IOException;
import java.nio.file.FileVisitResult;
import static java.nio.file.FileVisitResult.CONTINUE;
import java.nio.file.FileVisitor;
import java.nio.file.Path;
import java.nio.file.attribute.BasicFileAttributes;
public class PrintTree implements FileVisitor<Path> {
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attr) {
System.out.print("preVisitDirectory: ");
System.out.println("Directory : " + dir);
return CONTINUE;
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attr) {
System.out.print("visitFile: ");
System.out.print("File : " + file);
System.out.println("(" + attr.size() + " bytes)");
return CONTINUE;
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) {
System.out.print("postVisitDirectory: ");
System.out.println("Directory : " + dir);
return CONTINUE;
}
@Override
public FileVisitResult visitFileFailed(Path file, IOException exc) {
System.out.print("vistiFileFailed: ");
System.err.println(exc);
return CONTINUE;
}
}
A continuación se muestra un código de ejemplo utilizando la clase PrintTree:
Path path = Paths.get("D:/Test");
try{
Files.walkFileTree(path, new PrintTree())
} catch (IOException e) {
System.out.println("Exception: "+e);
}
En este ejemplo la clase PrintTree implanta cada uno de los métodos en FileVisitor e imprime el tipo, nombre y el tamaño del directorio y el archivo de cada nodo.
Búsqueda de Archivos
Clase PathMatcher
En java.nio.file se incluye la interfaz PathMatcher la cuál define el método matches(Parth path). Éste método permite determinar si un objeto Path coincide con una cadena de búsqueda especificada.Cada implantación de sistema de archivos proporciona un objeto PathMatcher recuperable mediante FileSystems:
PathMatcher matcher = FileSystems.getDefault().getPathMatcher(String syntaxPattern);
La cadena syntaxPattern presenta la siguiente forma sintaxis:patrón dónde sintaxis puede ser «glob» o «regex».Y cúando la sintaxis es «regex«, el componente patrón es una expresión regular definida por la clase Pattern.
Se incluye el siguiente código Java. Esta clase se utiliza para recorrer el árbol en busca de coincidencias entre el archivo y el archivo alcanzado por el método VisitFile.
package findingfiles;
import java.io.IOException;
import java.nio.file.FileVisitResult;
import static java.nio.file.FileVisitResult.CONTINUE;
import java.nio.file.FileVisitor;
import java.nio.file.Path;
import java.nio.file.PathMatcher;
import java.nio.file.attribute.BasicFileAttributes;
public class Finder implements FileVisitor<Path> {
private Path root;
private PathMatcher matcher;
Finder(Path root, PathMatcher matcher) {
this.root = root;
this.matcher = matcher;
}
private void find(Path file) {
Path name = file.getFileName();
if (name != null && matcher.matches(name)) {
System.out.println(file);
}
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) {
find(file);
return CONTINUE;
}
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) {
return CONTINUE;
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) {
return CONTINUE;
}
@Override
public FileVisitResult visitFileFailed(Path file, IOException exc) {
return CONTINUE;
}
}
Una vez definido el tipo, se instancia en una clase MyClass y se ejecuta.
package findingfiles;
import java.io.IOException;
import java.nio.file.*;
public class MyClass {
public static void main(String[] args) {
Path root = Paths.get("C:\JavaTest");
PathMatcher matcher = FileSystems.getDefault().getPathMatcher
("glob:*.{java,class}");
Finder finder = new Finder(root, matcher);
try {
Files.walkFileTree(root, finder);
} catch (IOException e) {
System.out.println("Exception: " + e);
}
}
}
El primer argumento se prueba para ver si es un directorio. El segundo argumento se usa para crear una instancia PatchMatcher con una expresión regular mediante la fábrica FileSystems.Finder es un clase que implanta la interfaz FileVisitor, de modo que se puede transferir a un método walkFileTree. Esta clase se usa para llamar al método de coincidencia en todos los archivos visitados en el árbol.
OCP7 10 – E/S de archivos Java – Parte 1 – NIO.2 (New Input Output 2)
NIO
Es el acrónimo de New Input Output.
NIO.2 del Jdk 1.7 implementa un nuevo paquete java.nio.file con dos subpaquetes:
–java.nio.file.attribute: Que permite un acceso masivo a los atributos de los archivos.
–java.nio.file.spi: Dónde SPI significa Service Provider Interface. Es una interfície que permite establecer la conexión de la implementación de varios sistemas de archivos, permitiendo al desarrollador crear su propia versión del proveedor de sistema de archivos si así lo requiere.
La clase FileSystem
Proporciona un método de intercomunicación con un sistema de archivos y un mecanismo para la creación de objetos usados para la manipulación de archivos y directorios.
Interface Path – java.nio.file.Path
Un objeto Path representa la ubicación relativa o absoluta de un archivo o directorio. A su vez, permite definir métodos para la localización de archivos o directorios dentro de un sistema de archivos.
En Windows nodo raíz c:
En Unix nodo raíz empieza con /
Puede encontrarse informació más detallada en la API oficial.
Métodos principales de la interfaz Path (se pueden encontrar más métodos en la URL oficial):
- getFileName(): Devuelve el nombre del archivo o del elemento más alejado del nodo raíz en la jerarquía de directorios.
- getParent(): Devuelve la ruta del directorio padre.
- getNameCount(): Devuelve el número de elementos que componen la ruta sin contar al elemento raíz.
- getRoot(): Devuelve el elemento raíz.
- normalize(): Elimina cualquier elemento redundante en la ruta.
- toUri(): Convierte una ruta en una cadena que puede ser introducida en la barra dirección web de un navegador.
- subpath(1, 3): Devuelve un objeto Path que representa una subsecuencia de la ruta origen. (Los números hacen referencia a los identificadores situados entre las / separadoras empezando por el 0).
- relativize(new Path()): Crea una ruta relativa entre la ruta y una ruta indicada. Caso de ejemplo: en un entorno UNIX, si la ruta es
"/a/b"y la ruta indicada es"/a/b/c/d"entonces la ruta relativa resultante será"c/d".
La clase Files – java.nio.file.Files
Esta clase contiene métodos estáticos los cuáles podemos utilizar para realizar operaciones en archivos o en directorios.
Puede encontrarse información más detallada en la API oficial.
La clase Files es sumamente importante para poder realizar operaciones con objetos Path tales como:
- Verificar un archivo o directorio.
- exists():
- notExists():
- isReadable(Path path): Comprobar si el archivo o directorio dispone de permisos de lectura.
- isWritable(Path path): Comprobar si el archivo o directorio dispone de permisos de escritura.
- isExecutable(Path path): Comprobar si el archivo o directorio dispone de permisos de ejecución.
- setAttribute(Path path, String attribute, Object value, LinkOption… options). Permite aplicar distintos atributos a ficheros en el sistema DOS. Ejemplo: Files.setAttribute(new Path(), «dos:readonly», true).
El siguiente código ejemplifica su utilización.
package filesclass;
import java.io.IOException;
import java.nio.file.*;
import java.util.Set;
public class FilesClass {
public static void main(String[] args) {
Path p1 = Paths.get("C:\JavaCourse\src\Example.java");
System.out.println("exists: " + Files.exists(p1));
System.out.println("isReadable: " + Files.isReadable(p1));
System.out.println("isWritable: " + Files.isWritable(p1));
System.out.println("isExecutable: " + Files.isExecutable(p1));
//Set<PosixFilePermission> perms = PosixFilePermissions.fromString("rwxr-x---");
//FileAttribute<Set<PosixFilePermission>> attr = PosixFilePermissions.asFileAttribute(perms);
try {
//Path f1 = Paths.get("C:\JavaCourse\src\Hello.txt");
//Files.createFile(f1, attr);
Files.setAttribute(p1, "dos:readonly", true);
System.out.println("Example.java isWritable: " + Files.isWritable(p1));
System.out.println(Files.createTempFile("test", ".temp"));
} catch (IOException e) {
System.err.println(e);
}
}
}
Adicionalmente se puede comprobar y modificar el nivel de accesibilidad de un archivo o directorio mediante los siguientes métodos
-
- createTempFile
- createTempFile(Path dir, String prefix, String suffix, FileAttribute<?>… attrs)
Crea un nuevo fichero vacío en el directorio especificado, utilizando los textos de prefixo y sufijo facilitados en la llamada de la función para generar su nombre. - static Path createTempFile(String prefix, String suffix, FileAttribute<?>… attrs) Crea un nombre vacío en el directorio temporal por defecto, utilizando el prefijo y sufijo facilitados para generar su nombre.
- createTempFile(Path dir, String prefix, String suffix, FileAttribute<?>… attrs)
- copy: Permite copiar un archivo de una ruta a otra.
- copy(InputStream in, Path target, CopyOption… options)
Copia todos los bytes de un flujo de datos de entrada (Stream) a un fichero. - copy(Path source, OutputStream out)
Copia todos los byters de un fichero a un flujo de datos de salida(Stream). - copy(Path source, Path target, CopyOption… options)
Copia un fichero a otro fichero.
- copy(InputStream in, Path target, CopyOption… options)
- delete(Path path): Permite borrar archivos físicos o lógicos.
- move(): Permite mover un archivo de una ruta a otra.
- newDirectoryStream(new Path()): Permite obtener una interfaz DirectoryStream que al heredar de Iterable permite iterar sobre todos los archivos o subdirectorios situados en el nodo raíz. Debe utilizarse try-with-resources o lo finalizaremos explícitamente. Puede lanzar la excepción DirectoryIteratorException o IOException.
- createTempFile
El siguiente código muestra un caso de ejemplo de borrado, copia y pegado de ficheros en Java7.
package filesclass;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.NoSuchFileException;
import java.nio.file.Path;
import java.nio.file.Paths;
import static java.nio.file.StandardCopyOption.REPLACE_EXISTING;
public class FilesClass2 {
public static void main(String[] args) {
Path f1 = Paths.get("C:\JavaCourse\src\Hello.txt");
Path f2 = Paths.get("C:\student\Hello2.txt");
try {
Files.copy(f1,f2,REPLACE_EXISTING);
Files.delete(f1);
Files.move(f2,f1,REPLACE_EXISTING);
System.out.println("Hello.txt exists: " + Files.exists(f1));
System.out.println("Hello2.txt exists: " + Files.exists(f2));
} catch (NoSuchFileException n) {
System.err.println(n);
} catch (IOException e) {
System.err.println(e);
}
}
}
Relación y conversión entre Path y File
Entre la Interface Path y la classe File existen mecanismos para obtener una representación de un tipo a el otro. En el JDK7 no es necesario realizar operaciones de conversión complejas solamente es necesario recurrir al método .toFile de cada uno de ellos:
- path.toFile(): Retorna un objeto File representando su ruta.
- file.toPath(): Retorna un objeto de tipo Path construido desde una ruta abstracta. El objeto Path resultante se encuentra asociado con el sistema de archivos por defecto.
Código fuente de ejemplo.
1 2 |
File file = path.toFile(); Path file = file.toPath(); |