Los sistemas modernos contienen varias CPU. Para sacar partido de la potencia de procesamiento en un sistema es preciso ejecutar tareas en paralelo en varias CPU.
Divide y vencerás.
Una tarea se debe dividir en subtareas. Debe intentar identificar aquellas subtareas que se puedan ejecutar en paralelo.
Puede ser difícil ejecutar algunos problemas como tareas paralelas.
Algunos problemas son más sencillos. Los servidores que soportan varios clientes pueden usar una tarea independiente para manejar cada cliente.
Se debe tener cuidado con el hardware. La programación de demasiadas tareas paralelas puede afectar de forma negativa al rendimiento.
Recuento de CPU
Si las tareas requieren muchos cálculos, al contrario de operaciones que generan muchas E/S, el número de tareas paralelas no debe superar en gran cantidad el número de procesadores del sistema.
Puede detectar el número de procesadores de forma sencilla en Java:
int count = Runtime.getRuntime().availableProcessors();
Sin paralelismo
Los sistemas modernos contienen varias CPU. Si no aprovechan los threads de alguna forma, sólo se utilizará una parte de la potencia de procesamiento del sistema.
Definición de etapa
Si tiene una gran cantidad de datos que procesar pero solo un thread para procesar dichos datos, se utilizará una CPU.
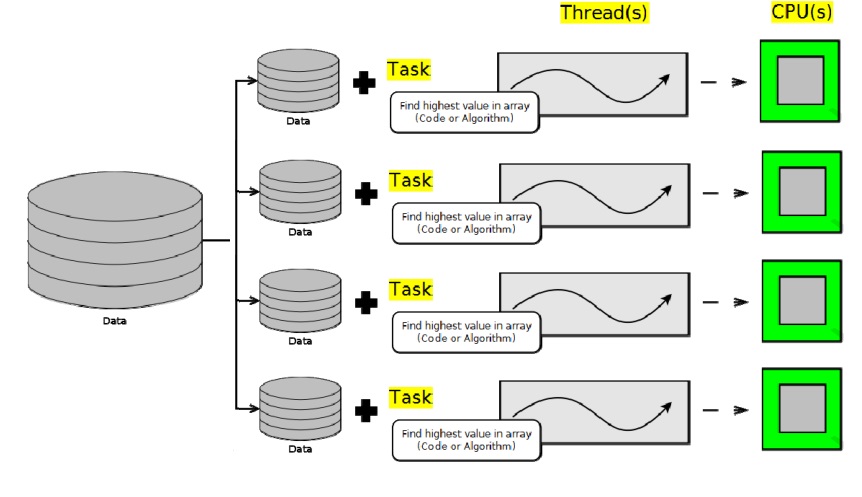
Como ejemplo el procesamiento de una matriz podría ser una tarea simple, como buscar el valor más alto en la matriz. Entonces, en un sistema de cuatro CPU, debe haber tres CPU inactivas mientras se procesa la matriz.
Paralelismo naive
Una solución paralela simple divide los datos que se van a procesar en varios juegos en un juego de datos para cada CPU y un thread para procesar cada juego de datos.
División de datos
Siguiendo el ejemplo de la matriz (como gran juego) se divide en cuatro subjuegos de datos, uno para cada CPU.
Ello implica que se crea un thread por CPU para procesar los datos.
Tras el procesamineto de los subjuegos de datos, los resultados se tendrán que combinar de una forma significativa.
Hay distintas forma de subdividir el juego de datos grande que se va a procesar.
Se usaría demasiada memoria para crear una matriz por thread que contenga una copia de una parte de la matriz original.
Cada matriz puede compartir una referencia a una única matriz grande pero solo acceder a un subjuego de una forma con protección de hread no bloqueante.
La diferencia conceptual entre forking y branching viene dada por desarrollo divergente vs convergente:
Concepto de Forking
Se refiere al proceso de generar una copia exacta del repositorio origen a uno nuevo en ese instante temporal. Es una copia física real y diferente, la operativa surge para realizar separaciones reales y crear nuevas lógicas bajo una base común, se asume que es poco probable que vuelvan a reunirse con el parent.
Concepto de Branching
Se refiere a generar un copia del repositorio dentro del mismo repositorio origen, un pointer. Las ramas son espacios temporales sobre los que cuales realizar desarrollos nuevos o cambios. Su objetivo es volver a converger con el repositorio siempre.
La diferencia conceptual es el scope de la copia (copia separada del parent o dentro de éste) y vida (vida independiente contra tiempo de vida efímero).
La razón de la diferencia parece ser la necesidad de controlar quién puede o no realizar push de código a la rama principal, la práctica del forkeo es más común en el open source cuando los posibles colaboradores no tienen permisos sobre el repositorio original, de ahí la copia que genera otro repositorio de facto y luego la posibilidad de converger con el parent o no.
Diferencias
Forking es más costoso al tener que comparar dos codebases una contra la otra, ya que el fork representa una copia literal del repositorio original (doble de espacio de almacenamiento).
Branching sólo añade una rama sobre el árbol actual, el tamaño de la rama viene ligada literalmente a los cambios de ésta.
Forking ofusca más ver en que anda trabajabando el equipo, al tener que moverse entre repositorios distintos en vez de sobre ramas sobre uno solo repositorio.
Forking al no ser un workflow colaborativo, los cambios residen en la copia de cada uno y puede llevar a mayores problemas a la hora de mergear, perecer (políticas internas de la casa para autoborrado de forks por falta de uso para liberar espacio…) o pérdida de conocimiento.
Branching al centralizar el workflow sobre un sólo repositorio permite, al actualizar sus copias, 1 remote recibir el estado de todos los remotos de las features de sus compañeros.
Why?
The Bitbucket team recommends branching for development teams on Bitbucket.
— Bitbucket
[…]People refer to Git’s branching model as its “killer feature,” and it certainly sets Git apart in the VCS community. Why is it so special? The way Git branches is incredibly lightweight, making branching operations nearly instantaneous, and switching back and forth between branches generally just as fast. Unlike many other VCSs, Git encourages workflows that branch and merge often, even multiple times in a day.
Pro Git Book by Scott Chachon and Ben Straub
Aparte de una diferencia de estilo de trabajo, de que conceptualmente los forks son para otra cosa, y el coste real es espacio en disco y tiempo de copia… en realidad ambas operativas son similares e incluso complementarias, no excluyentes.
Razón
La razón para utilizar únicamente branches es:
Una forma más rápida y cómoda de recorrer el código (1 repositorio, 7 ramas de feature; en vez de bajarse 7 forks y sin saber si existirán más ramas dentro del fork).
Implementar GitFlow o una aproximación a éste en nuestra forma de trabajar de forma más realista.
Requerimientos
Para poder empezar a trabajar con branches sin repercutir en la productividad deben tenerse en cuenta los siguientes pasos:
Plan fijado de sobre como implementar la CI en las branches.
Protección de ramas a commit de developers.
hotfix branches, quién, cómo se crean y cierran.
release branches.
master es productivo.
preproducción queda atada a release branches o se puede añadir una branch específica para preproducción sobre cada release.
Pipelines de la CI/CD.
Activación automática de la CI en branches.
En vez de activación por commit en master de los forks, que se activen también por commit en branches.
Para reducir ejecuciones podría restringirse la ejecución manual de la CI en las ramas feature.
Nota: Los ejemplos mostrados en este artículo suponen la utilización de arquitecturas de CPU que soportan operaciones de definición y comparación atómicas (operaciones Compare And Swap), como por ejemplo los procesadores x86 o Sparc actuales. En este caso las operaciones lock / unlock serán operaciones no bloqueantes. Otras arquitecturas que no soporten esta funcionalidad pueden requerir alguna forma de bloqueo interno por parte de la plataforma.
Paquete java.util.concurrent.locks
El paquete java.util.concurrent.locks es un marco para bloquear y esperar condiciones que es distinto de las supervisiones y sincronización incorporadas.
Bloqueo de varios lectores y un único escritor
public class ShoppingCart {
private final ReentrantReadWriteLock rw1 = new ReentrantReadWriteLock();
public void addItem (Object o) {
rw1.writeLock().lock();
// source code to modify shopping cart
rw1.writeLock().unlock();
}
} // End class ShoppingCart
El código fuente en main() que implementa el bloqueo y el desbloqueo es el siguiente junto con el código fuente para realizar las modificaciones del shopping cart:
rw1.writeLock().lock();
// source code to modify shopping cart
rw1.writeLock().unlock();
realizando el bloqueo de escritura.
Describiendo un poco todo lo documentado, una de la funciones del paquete java.util.concurrent.locks es la implantación de un bloqueo de varios lectores con un único escritor.
Es posible que un thread no tenga ni obtenga un bloqueo de lectura mientras está en uso el bloqueo de escritura.
Varios threads pueden adquirir simultáneamente el bloqueo de lectura pero sólo uno de ellos puede adquirir el bloqueo de escritura (n -lecturas <-> 1 escritura).
El bloqueo es reentrante: un thread que ya adquirido el bloqueo de escritura puede llamar a métodos adicionales que también obtengan el bloqueo de escritura sin miedo a que se produzca un bloqueo.
Bloqueo de lectura (sin ningún escritor)
Ejemplo dónde se muestra como los métodos de lectura son concurrentes:
public class ShoppingCart {
public String getSummary() {
String s = "";
rw1.readLock().lock();
// Source code to read cart, modify s
rw1.readLock().unlock();
return s;
}
// Todos los métodos de sólo lectura se pueden ejecutar de forma simultánea
public double getTotal () {
// another read-only method
}
} // End class ShoppingCart
En el ejemplo todos los métodos determinados como de sólo lectura pueden agregar el código necesario para bloquear y desbloquear un bloqueo de lectura.
ReentrantReadWriteLock permite la ejecución simultánea de ambos, dónde puede ejecutar un único método de sólo lectura o varios métodos de sólo lectura concurrentes.
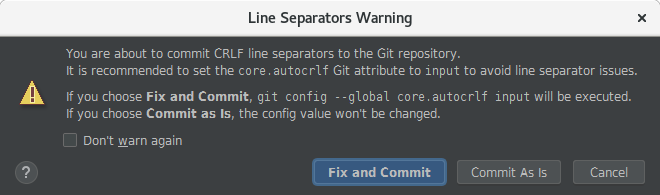
Sometimes a new problem could appear regarding the end of line on files using an IDE (like IntelliJ for example) when doing a Commit&Push into Master through Git.
When this situation happens a new window may popup:
It is recommended the use of the option "commit as it is" by default.
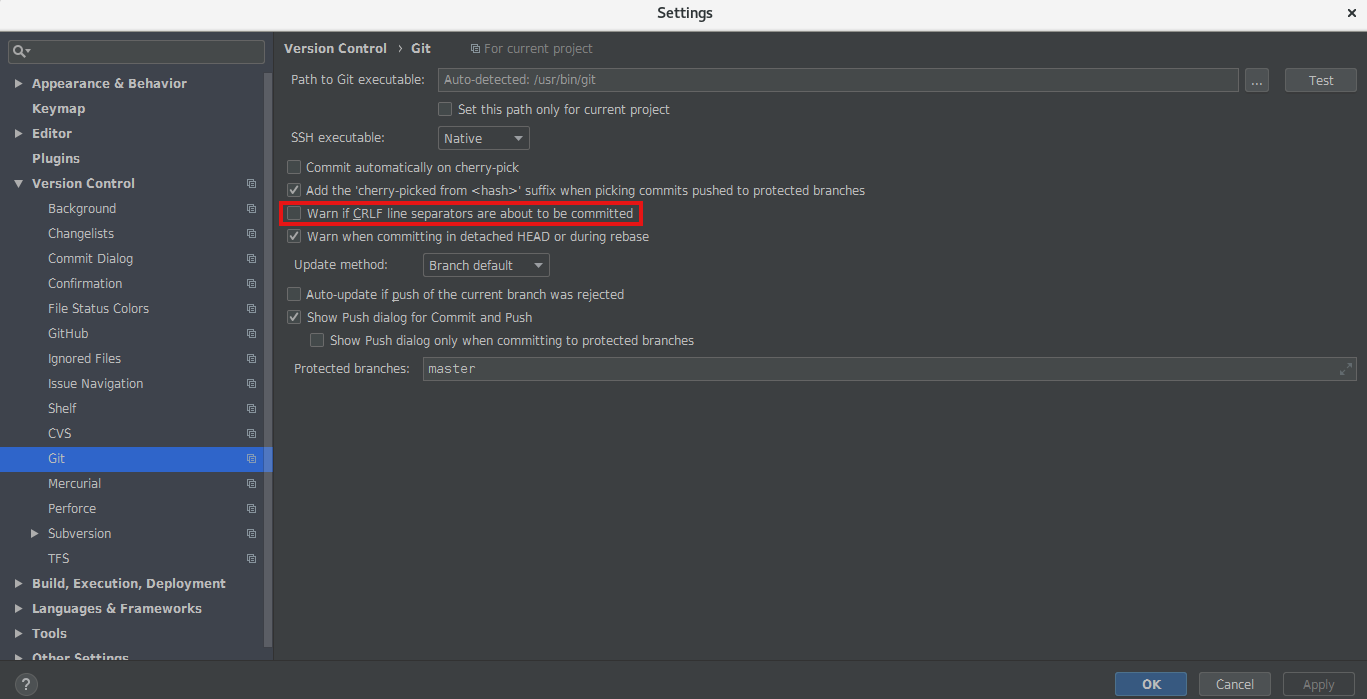
Be sure to uncheck the setting ‘Warn if CRLF line separators are about to be commited to avoid the warning popup‘ in case of using the IntelliJ IDE.
To prevent git from automatically changing the line endings on your files in general is enough running this command:
git config --global core.autocrlf false
BUt a general solution that force one customized configuration is the creation of a new file in the root folder of the project called .gitattributes.
This is its content:
* text eol=crlf working-tree-encoding=UTF-8
*.java text eol=crlf working-tree-encoding=UTF-8
*.xml text eol=crlf working-tree-encoding=UTF-8
*.properties text eol=crlf working-tree-encoding=UTF-8
*.jsp text eol=crlf working-tree-encoding=UTF-8
*.sql text eol=crlf working-tree-encoding=UTF-8
It’s important to point out that this configuration can be changed and adapted to a different one depending on the necessities of the project.
En general las colecciones de java.util no tienen protección de thread. Para poder utilizar colecciones en modo de protección de thread se debe utilizar uno de los siguientes mecanismos:
Utilizar bloques de código sincronizado para todos los accesos a una colección si se realizan escrituras.
Crear un envoltorio sincronizado mediante métodos de biblioteca como java.util.Collections.synchronizedList(List<T>). Es importante destacar que el hecho de que una Collection se cree con protección thread no hace que sus elementos dispongan de la misma protección de thread.
Utilizar colecciones dentro de java.util.concurrent.
La clase ConcurrentLinkedQueue proporciona una cola FIFO no bloqueante con protección de thread escalable eficaz.
Adicionalmente existen cinco implementaciones en java.util.concurrent que también soportan la interfaz ampliada BlockingQueue que define las versiones de bloqueo de colocación y captura:
Para poder anidar distintos objetos de negocio dentro del Swagger, el primer paso consiste en añadir éstos en la sección definitions del Swagger.
Aquí deben declararse todos los que se van a utilizar para crear la lista de objetos de tipo Element según el ejemplo que se ha desarrollado.
Una vez añadidas las definiciones se añade al Swagger el siguiente código:
ElementList:
type: array
description: Elements List.
items:
$ref: '#/definitions/Element'
Type indica a Swagger que el elemento contenido es de tipo array. Description describe la lista de elementos de la lista. items:
$ref: '#/definitions/Element'
Con esta sintaxis se indica a Swagger que cada elemento de la lista ElementList se corresponde con una definición de objeto de negocio cuya definición també aparecerá cuándo Swagger muestre el modelo general.
Se pueden anidar varios niveles en la creación de un objeto complejo. En el caso de ejemplo que se describe en el apartado siguiente se puede visualizar tres niveles: ElementList -> Element que contiene a su vez listas del tipo Acces e Invoice.
Ejemplo
Código de ejemplo:
swagger: '2.0'
paths:
'/MainEndpoint/{element}':
get:
summary: Getting information of the service.
description: >-
Description of the swagger service.
parameters:
- name: element
in: path
required: true
type: string
description: Element Id separated by commas.
responses:
'200':
description: Specific element.
schema:
properties:
sources:
type: array
items:
$ref: '#/definitions/ElementList'
default:
description: Unexpected error
schema:
$ref: '#/definitions/Error'
x-auth-type: None
x-throttling-tier: Unlimited
/MainEndpoint:
get:
summary: Get the whole elements.
description: |
Get all the elements available.
responses:
'200':
description: All the elements
schema:
properties:
sources:
title: ElementList
type: array
items:
$ref: '#/definitions/ElementList'
default:
description: Unexpected error
schema:
$ref: '#/definitions/Error'
x-auth-type: None
x-throttling-tier: Unlimited
definitions:
Error:
type: object
properties:
code:
type: integer
format: int32
message:
type: string
fields:
type: string
ElementList:
type: array
description: Elements List.
items:
$ref: '#/definitions/Element'
Element:
type: object
description: Element.
properties:
elementCode:
type: string
example: 5000
name:
type: string
example: Door
address:
type: string
example: Jumper Street number 65
elementaccess:
type: array
description: Acces element.
items:
$ref: '#/definitions/Access'
maxwidth:
type: integer
format: int32
example: 250
maxheight:
type: integer
format: int32
example: 100
saved:
type: boolean
example: 1
informationpoint:
type: boolean
example: 0
open:
type: string
example: 1
close:
type: string
example: 1
exterior:
type: boolean
example: 0
elevator:
type: boolean
example: 1
elementinvoicelist:
type: array
description: Element invoice.
items:
$ref: '#/definitions/Invoice'
argumentelement:
type: integer
format: int32
example: 30
Invoice:
type: object
properties:
invoicetype:
type: string
example: Custom
descinvoicetype:
type: string
example: 7 days
elementtype:
type: string
example: ElementType
amount:
type: number
format: float
example: 50,35
minutes:
type: integer
format: int32
example: 15
Access:
type: object
properties:
accessid:
type: string
example: 45
accessaddress:
type: string
example: Boeing Street number 126.
info:
title: Endpoint Title
version: v1
description: >-
Description related with the endpoint
securityDefinitions:
default:
type: oauth2
authorizationUrl: 'https://127.0.0.1:8080/authorize'
flow: implicit
scopes: {}
basePath: /Base/PathService/Element/v1
host: '127.0.01:8080'
schemes:
- https
- http
En este artículo se exponen los mecanismos básicos que proporciona la plataforma estándar de Java para la implementación de tareas concurrentes detallada para su versión 7.
Se tratarán los siguientes conceptos:
Implementación de tareas mediante hilos de ejecución
Gestión del ciclo de vida de los hilos de ejecución mediante API
En la medida de lo posible se deberá hacer uso de la jerarquía de excepciones provistas por la JDK. En caso de querer crear nuevos tipos, se deberán tener en cuenta los siguientes puntos:
Extender de RuntimeException o una de sus subclases en caso de definir un tipo de error no recuperable (Excepción no comprobada).
Extender de Exception o una de sus subclases (a excepción de RuntimeException) en caso de definir un tipo de error recuperable (Excepción comprobada) que debe ser explícitamente declarado y capturado.
No extender directamente de la clase Throwable, ya que la mayoría de tratamientos de errores mediante bloques try/catch se hace como mínimo a nivel de Exception. En estos casos, las excepciones derivadas directamente de Throwable no serían capturadas por estos bloques lo que podría provocar efectos no previstos.