En la medida de lo posible se deberá hacer uso de la jerarquía de excepciones provistas por la JDK. En caso de querer crear nuevos tipos, se deberán tener en cuenta los siguientes puntos:
Extender de RuntimeException o una de sus subclases en caso de definir un tipo de error no recuperable (Excepción no comprobada).
Extender de Exception o una de sus subclases (a excepción de RuntimeException) en caso de definir un tipo de error recuperable (Excepción comprobada) que debe ser explícitamente declarado y capturado.
No extender directamente de la clase Throwable, ya que la mayoría de tratamientos de errores mediante bloques try/catch se hace como mínimo a nivel de Exception. En estos casos, las excepciones derivadas directamente de Throwable no serían capturadas por estos bloques lo que podría provocar efectos no previstos.
Las especificaciones para el uso de recursos en formato de fichero de propiedades a través de la API ResourceBundle de Java definen unas reglas para la nomenclatura y ubicación de dichos ficheros que hay que seguir de forma que la JVM pueda localizar y recuperar los recursos definidos en ellos. No obstante, dicha API proporciona mecanismos que permiten personalizar este proceso. En este POST se explica cómo hacerlo.Seguir leyendo OCP7 13 – Localización (II)→
Los patrones de diseño consisten en soluciones reutilizables a problemas comunes en el desarrollo de software.
Estas soluciones se encuentran ampliamente documentadas y pretenden formalizar el vocabulario usado para hablar del diseño de software.
Patrón Singleton
Persigue el objetivo de mejorar el rendimiento de una aplicación impidiendo la creación de varias instancias de una clase.
Para la implementación de este patrón se utilizará una clase con una variable de referencia estática:
public class SingletonClass {
private static final SingletonClass instance = new SingletonClass();
private SingletonClass() {}
public static SingletonClass getInstance() {
return instance;
}
}
la cual contendrá la única instancia de la clase. También se marca esta variable como final para que no pueda ser reasignada una instancia diferente.
Se añade un constructor privado private SingletonClass() {} de modo que sólo se permita el acceso a él des de la misma clase impidiendo cualquier intento de instanciarla de nuevo.
Por último se añade un método público y estático el cuál podrá acceder al campo estático y devolver su valor.
public static SingletonClass getInstance() {
return instance;
}
Mediante este método se puede recuperar la instacia creada cuándo sea requerido el objeto que implementa la clase Singleton.
Patrón Dao (Data-Acces-Object)
Es un patrón de diseño ampliamente conocido que separa la lógica de negocio de la persistencia de los datos.Permite una mayor facilidad de implementación del código y una mayor sencillez de mantenimiento del mismo. A su vez es más escalable y ampliable.
Patrón Factory
Patrón de diseño que separala clase que crea los objetos de la jerarquía de los objetos a instanciar dentro del espacio de memoria
Los objetivos intenta conseguir consisten en:
-Una centralización de la creación de los objetos en memoria.
–Escalabilidad del Sistema.
–Abstracción del usuario sobre la instancia a crear.
Un ejemplo de implementación del patrón Factoria es el siguiente:
EmployeeDAOFactory factory = new EmployeeDAOFactory();
EmployeeDAOFactory dao = factory.createEmployeeDAOFactory();
Mediante este patrón de diseño Factory se impide que una aplicación se vincule a una aplicación específica implementadora del Patrón Dao.
Se debe evitar la duplicación de código siempre que se pueda y refactorizar al máximo posible sin poner en riesgo la funcionalidad de la aplicación y dejándola intacta. La Factoría permite obtener estos resultados de una forma eficiente.
Patrón Cadena de Responsabilidad
El patrón de diseño Cadena de Responsabilidad (Chain of Responsability) es un patrón de tipo «comportamiento», es decir, que establece protocolos de interacción entre clases y objetos emisores y receptores de los mensajes a procesar. Se utiliza para desacoplar las diferentes implementaciones de un algoritmo de su uso final, ya que el emisor del mensaje no tiene porqué conocer el componente que finalmente procesará el mensaje.
Se forma una lista encadenada con todos los posibles receptores del mensaje, de forma que cada uno de ellos dispone de un enlace al siguiente, si se quiere, ordenados pueden ordenarse por prioridad de forma que en caso de que varios de ellos sean capaces de procesar un mismo mensaje, prevalezca el que tenga una prioridad mas alta según criterios funcionales.
El emisor del mensaje, sólo ha de tener acceso al primero de los receptores. Será a este al que se le hará la llamada inicial y quien proporcionará el resultado al emisor.
Cada uno de los receptores, evaluará el mensaje proporcionado por el emisor y decidirá si es capaz de procesarlo y proporcionar un resultado. En caso afirmativo, se acabará la cadena de llamadas a posteriores receptores y se retornará. Esto hará que el resultado pase por todos los receptores ejecutados anteriormente hasta devolvérselo al emisor. En caso que el receptor actual no sea capaz de evaluar el mensaje, delegará en el siguiente receptor en la cadena esperando el resultado que le proporcione, sea él o no el que finalmente se haga cargo de proporcionárselo.
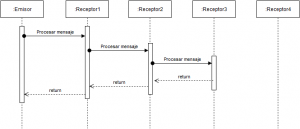
El siguiente diagrama de secuencia ilustra los puntos detallados con anterioridad:
En él se puede observar una situación en la que se dispone de un emisor y 4 receptores capaces de procesar diferentes mensajes. El emisor hace la llamada al primer de los receptores para que le proporcione el resultado. Éste, al evaluarlo, ve que no es capaz de procesarlo y delega en el segundo de los receptores y así sucesivamente hasta llegar al tercero de ellos, que si es capaz de hacerlo y proporciona un resultado, haciendo innecesaria la propagación del mensaje al cuarto de ellos. El resultado se propaga por los receptores 1 y 2 hasta llegar al emisor de forma transparente.
La clase FileStorees útil para proporcionar información de uso sobre el sistema de archivos como el total de disco utilizable y asignado.
Filesystem kbytes used available
System (C:) 209748988 72247420 137501568
Data (D:) 81847292 429488 81417804
En este enlace oficial de Oracle puede estudiarse la implementación de FileStore.
Interfaz WatchService
La implementación de la interfaz de WatchService representa un servicio de vigilancia que observa los cambios producidos en los objetos Path registrados.
Por ejemplo, una instancia de WatchService puede usarse para identificar cuándo fueron añadidos, borrados o modificados archivos en un directorio.
ENTRY_CREATE: D:testNew Text Document.txt
ENTRY_CREATE: D:testFoo.txt
ENTRY_MODIFY: D:testFoo.txt
ENTRY_MODIFY: D:testFoo.txt
ENTRY_DELETE: D:testFoo.txt
NOTA:
La implementación del mecanismo de observación del sistema de ficheros es dependiente de la plataforma de ejecución.
Por defecto, se intentan mapear los eventos que se observan a través del WatchService con los eventos nativos que el Sistema Operativo genera ante los cambios de ficheros. Esto hace que sea posible encontrarse diferentes tipos de eventos resultados de una misma acción.
En caso que no sea posible consumir los eventos nativos, la implementación en caso de error se encargará de polling consultar el estado de los elementos del sistema de ficheros indicado.
La contra partida de este mecanismo de fallback es que ante eventos muy seguidos, es posible que no se reciban todos los eventos generados si el tiempo entre muestra y muestra es superior al tiempo transcurrido entre los eventos.
En todo caso, la utilización de este servicio ha de tener en cuenta esta particularidad para no obtener resultados inesperados.
En este enlace oficial de Oracle puede estudiarse con más detalle el funcionamiento de la interfaz WatchService.
La classe Files ofrece un método para recorrer el árbol de archivos en busca de operaciones recursivas, como de copia y de supresión.
Interfaz FileVisitor<T>
La interfaz FileVisitor<T> permite realizar el recorrido de un nodo raíz de forma recursiva. Puede encontrarse la implementación en la API del JDK 7 en el siguiente enlace.
Para poder llevar a cabo el recorrido recursivo mencionado con anterioridad se detallan los siguientes métodos, representando puntos clave del recorrido recursivo. Son métodos a los que se vaya llamando cada vez que se visita uno de los nodos del árbol:
El objeto FileVisitResult es el tipo de retorno para la interfaz FileVisitor. Contiene cuatro constantes que permiten procesar el archivo visitado e indicar que debe ocurrir en el próximo archivo (Enum FileVisitResult – para un mayor detalle se puede consultar directamente la API de JDK 7 en este enlace). Estas constantes representan las acciones que tomar tras alcanzar un nodo (antes o después):
CONTINUE: Se debe continuar la visita del siguiente nodo en el árbol de directorios.
SKIP_SIBLINGS: Señala que se debe continuar el recorrido sin visitar a los hermanos del archivo o directorio.
SKIP_SUBTREE: Señala que se debe continuar el recorrido de los nodos sin visitar las entradas de este directorio.
TERMINATE: Indica la finalización del proceso de visita.
A continuación se muestra un código Java que ilustra la utilización de los cuatro métodos definidos con anterioridad:
En este ejemplo la clase PrintTree implanta cada uno de los métodos en FileVisitor e imprime el tipo, nombre y el tamaño del directorio y el archivo de cada nodo.
Búsqueda de Archivos
Clase PathMatcher
En java.nio.file se incluye la interfaz PathMatcher la cuál define el método matches(Parth path). Éste método permite determinar si un objeto Path coincide con una cadena de búsqueda especificada.Cada implantación de sistema de archivos proporciona un objeto PathMatcherrecuperable mediante FileSystems:
La cadena syntaxPattern presenta la siguiente forma sintaxis:patrón dónde sintaxis puede ser «glob» o «regex».Y cúando la sintaxis es «regex«, el componente patrón es una expresión regular definida por la clase Pattern.
Se incluye el siguiente código Java. Esta clase se utiliza para recorrer el árbol en busca de coincidencias entre el archivo y el archivo alcanzado por el método VisitFile.
Una vez definido el tipo, se instancia en una clase MyClass y se ejecuta.
package findingfiles;
import java.io.IOException;
import java.nio.file.*;
public class MyClass {
public static void main(String[] args) {
Path root = Paths.get("C:\JavaTest");
PathMatcher matcher = FileSystems.getDefault().getPathMatcher
("glob:*.{java,class}");
Finder finder = new Finder(root, matcher);
try {
Files.walkFileTree(root, finder);
} catch (IOException e) {
System.out.println("Exception: " + e);
}
}
}
El primer argumento se prueba para ver si es un directorio. El segundo argumento se usa para crear una instancia PatchMatcher con una expresión regular mediante la fábrica FileSystems.Finder es un clase que implanta la interfaz FileVisitor, de modo que se puede transferir a un método walkFileTree. Esta clase se usa para llamar al método de coincidencia en todos los archivos visitados en el árbol.
NIO.2 del Jdk 1.7 implementa un nuevo paquete java.nio.file con dos subpaquetes:
–java.nio.file.attribute: Que permite un acceso masivo a los atributos de los archivos.
–java.nio.file.spi: Dónde SPI significa Service Provider Interface. Es una interfície que permite establecer la conexión de la implementación de varios sistemas de archivos, permitiendo al desarrollador crear su propia versión del proveedor de sistema de archivos si así lo requiere.
La clase FileSystem
Proporciona un método de intercomunicación con un sistema de archivos y un mecanismo para la creación de objetos usados para la manipulación de archivos y directorios.
Interface Path – java.nio.file.Path
Un objeto Path representa la ubicación relativa o absoluta de un archivo o directorio. A su vez, permite definir métodos para la localización de archivos o directorios dentro de un sistema de archivos.
En Windows nodo raíz c:
En Unix nodo raíz empieza con /
Puede encontrarse informació más detallada en la API oficial.
Métodos principales de la interfaz Path (se pueden encontrar más métodos en la URL oficial):
getFileName(): Devuelve el nombre del archivo o del elemento más alejado del nodo raíz en la jerarquía de directorios.
getParent(): Devuelve la ruta del directorio padre.
getNameCount(): Devuelve el número de elementos que componen la ruta sin contar al elemento raíz.
normalize(): Elimina cualquier elemento redundante en la ruta.
toUri(): Convierte una ruta en una cadena que puede ser introducida en la barra dirección web de un navegador.
subpath(1, 3): Devuelve un objeto Path que representa una subsecuencia de la ruta origen. (Los números hacen referencia a los identificadores situados entre las / separadoras empezando por el 0).
relativize(new Path()): Crea una ruta relativa entre la ruta y una ruta indicada. Caso de ejemplo: en un entorno UNIX, si la ruta es "/a/b" y la ruta indicada es "/a/b/c/d" entonces la ruta relativa resultante será "c/d".
La clase Files – java.nio.file.Files
Esta clase contiene métodos estáticos los cuáles podemos utilizar para realizar operaciones en archivos o en directorios.
Puede encontrarse información más detallada en la API oficial.
La clase Files es sumamente importante para poder realizar operaciones con objetos Path tales como:
Verificar un archivo o directorio.
exists():
notExists():
isReadable(Path path): Comprobar si el archivo o directorio dispone de permisos de lectura.
isWritable(Path path): Comprobar si el archivo o directorio dispone de permisos de escritura.
isExecutable(Path path):Comprobar si el archivo o directorio dispone de permisos de ejecución.
setAttribute(Path path, String attribute, Object value, LinkOption… options). Permite aplicar distintos atributos a ficheros en el sistema DOS. Ejemplo: Files.setAttribute(new Path(), «dos:readonly», true).
Adicionalmente se puede comprobar y modificar el nivel de accesibilidad de un archivo o directorio mediante los siguientes métodos
createTempFile
createTempFile(Path dir, String prefix, String suffix, FileAttribute<?>… attrs)
Crea un nuevo fichero vacío en el directorio especificado, utilizando los textos de prefixo y sufijo facilitados en la llamada de la función para generar su nombre.
static Path createTempFile(String prefix, String suffix, FileAttribute<?>… attrs) Crea un nombre vacío en el directorio temporal por defecto, utilizando el prefijo y sufijo facilitados para generar su nombre.
copy: Permite copiar un archivo de una ruta a otra.
copy(InputStream in, Path target, CopyOption… options)
Copia todos los bytes de un flujo de datos de entrada (Stream) a un fichero.
copy(Path source, OutputStream out)
Copia todos los byters de un fichero a un flujo de datos de salida(Stream).
copy(Path source, Path target, CopyOption… options)
Copia un fichero a otro fichero.
delete(Path path): Permite borrar archivos físicos o lógicos.
move(): Permite mover un archivo de una ruta a otra.
newDirectoryStream(new Path()): Permite obtener una interfaz DirectoryStream que al heredar de Iterable permite iterar sobre todos los archivos o subdirectorios situados en el nodo raíz. Debe utilizarse try-with-resources o lo finalizaremos explícitamente. Puede lanzar la excepción DirectoryIteratorException o IOException.
El siguiente código muestra un caso de ejemplo de borrado, copia y pegado de ficheros en Java7.
Entre la Interface Path y la classe File existen mecanismos para obtener una representación de un tipo a el otro. En el JDK7 no es necesario realizar operaciones de conversión complejas solamente es necesario recurrir al método .toFile de cada uno de ellos:
path.toFile(): Retorna un objeto File representando su ruta.
file.toPath(): Retorna un objeto de tipo Path construido desde una ruta abstracta. El objeto Path resultante se encuentra asociado con el sistema de archivos por defecto.
Los objetos genéricos se describen de forma abstracta mediante la siguiente notación:
Objetos Genéricos <T>
Por convención en Java dentro del operador diamante se ha establecido la siguiente convención:
T – Tipo
E – Elemento
K – Key
V – Valor
S, U – Se emplea si hay 2, 3 o más tipos definidos.
El Operador Diamante es<..> y permite evitar el uso del tipo genérico T en la construcción de un objeto dado que a partir de su declaración se infiere el tipo T asociado. Además, el operador simplifica y mejora la lectura del código fuente.
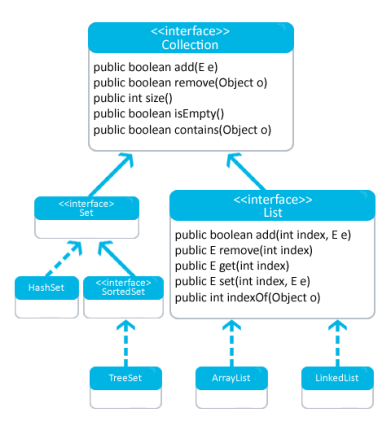
Tipos de Colecciones
Una colección es un objeto único que maneja un grupo de objetos. A esta agrupación de objetos también les llamamos elementos, tienen operaciones de inserción, borrado y consulta.
El framework de colecciones en Java es un arquitectura unificada que representa y maneja las colecciones independientemente de los detalles de implementación. Implementan pilas, colas, etc… y sus clases se almacenan en java.util.
Fig. 1 Detalle Interfície Colecciones.
List
Una lista es una interfaz que define el comportamiento de una lista genérica. Colecciónordenada en que cada elemento ocupa una posición identificada por un índice. Las listas crecen de formadinámica. Se pueden añadir, eliminar, sobrescribirelementosexistentes, y se permiten elementos duplicados.
List<T> lista = new ArrayList<>(3)
Un ArrayList es la implementación más conocida de una Collection, aunque también existen LinkedList y otras implementacions no detalladas en este post. En este enlace se puede profundizar en su conocimiento de forma más exahustiva.
Además de List existe otra interfície que deriva de Collection llamada Set cuyas implementaciones más conocidas son Hashset y TreeSet (implementación ésta de la interfaz SortedSet).
Existe una tercera interfaz que también deriva de Collection llamada Queue. En este enlace puede encontrarse información más detallada.
Para un mayor detalle y nivel de profundidad respecto a la clase Collections de Oracle, puede consultarse su documentación oficial online en este enlace para el JDK 7.
Autoboxing & Unboxing
Los tipos primitivos (int , float, double, etc…..) usados en Java no forman parte de su jerarquía de clases por cuestiones de eficiencia.
Java permite un mecanismo de envoltura llamado Wrapper para poder encapsular un tipo primitivo en un objeto. Una vez encapsulado dicho tipo primitivo, su valor puede ser recuperado mediante los métodosasociados a la clase de envoltura.
Nomenclatura de los procesos:
AutoBoxing: Encapsular el valor de un tipo primitivo en un objeto Wrapper.
Unboxing: Extraer el valor de un tipo primitivo de un objeto Wrapper.
Su utilización simplifica la sintaxis y produce código más limpio y legible para los programadores.
import java.util.ArrayList;
import java.util.List;
public class UnboxingAndAutoboxing {
public static void main(String[] args) {
// Autoboxing
int inNumber=50;
Integer a2 = new Integer(a); //Boxing
Integer a3 = 5; //Boxing
System.out.println(a2+" "+a3);
// Unboxing
Integer i = new Integer(-8);
// 1. Unboxing through method invocation
int absVal = absoluteValue(i);
System.out.println("absolute value of " + i + " = " + absVal);
List<Double> ld = new ArrayList<>();
ld.add(3.1416); // Π is autoboxed through method invocation.
// 2. Unboxing through assignment
double pi = ld.get(0);
System.out.println("pi = " + pi);
}
public static int absoluteValue(int i) {
return (i < 0) ? -i : i;
}
}
El término define una corriente de datos de una fuente a un destino.
Todos los datos fluyen a través de un ordenador desde una entrada (fuente) hacia una salida (destino).
Los fuentes y destinos de datos son nodos de los flujos en la comunicación del ordenador. Todos los flujos presentan el mismo modelo a todos los programas Java que los utilizan:
–flujo de entrada: para leer secuencialmente datos desde una fuente (un archivo, un teclado por ejemplo). Llamado también como input stream.
–flujo de salida: para escribir secuencialmente datos a un destino (una pantalla, archivo, etc). Llamado también como outputstream.
Estos nodos pueden ser representados por una fuente de datos, un programa, un flujo, etc..
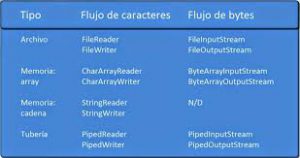
Flujos de Datos (Bytes y carácteres)
La tecnología Java admite dos tipos de datos en los flujos: bytes y carácteres.
Fig. 1 Tipos de Datos admitidos en Java
En el lenguaje Java los flujos de datos se detallan mediante clases que forman jerarquías según sea el tipo de dato char Unicode de 16 bits o byte de 8 bits.
A su vez, las clases se agrupan en jerarquías según sea su función de lectura (Read) o de escritura (Write).
La mayoría de las clases que se utilizan con Streams se encuentran ubicadas en el paquete java.io. En la cabecera del código fuente debe escribirse el importe del paquete import java.io.*;
Los tipos fundamentales de nodos o elementos a los que puede entrar y salir un flujo de datos que se pueden encontrar en el JDK 1.7 de Java son los siguientes:
Fig. 2 Tipos fundamentales de elementos en un flujo de datos
Todos los flujos deben cerrarse una vez haya finalizado su uso, forzando un close dentro de la cláusula finally.
Flujos en Memoria Intermedia
Para la lectura de archivos cortos de texto es mejor utilizar FileInputStreamen conjunción con FileReader. A continuación se añaden algunos ejemplos con código fuente para la memoria intermedia.
1.-Ejemplo TestBufferedStreams
package bufferedstreams;
import java.io.*;
public class TestBufferedStreams {
public static void main(String[] args) {
try (
BufferedReader bufInput =
new BufferedReader(new FileReader("src\bufferedstreams\file1.txt"));
BufferedWriter bufOutput =
new BufferedWriter(new FileWriter("src\bufferedstreams\file2.txt"))
){
String line = bufInput.readLine();
while (line != null) {
bufOutput.write(line, 0, line.length());
bufOutput.newLine();
line = bufInput.readLine();
}
} catch (IOException e) {
System.out.println("Exception: " + e);
}
}
}
2.-Ejemplo TestCharactersStreams
package bufferedstreams;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class TestCharactersStreams {
public static void main(String[] args) {
try (FileReader input = new FileReader("src\bufferedstreams\file1.txt");
FileWriter output = new FileWriter("src\bufferedstreams\file2.txt")) {
int charsRead;
while ((charsRead = input.read()) != -1) {
output.write(charsRead);
}
} catch (IOException e) {
System.out.println("IOException: " + e);
}
}
}
Ejemplo de entrada y salida estándar
Existen en Java 7 tres flujos estándar principales:
System.in. Campo estático de entrada de tipo InputStream lo que permite leer desde la entrada estándar.
System.out. Campo estático de salida de tipo PrintStream lo que permite escribir en la salida estándar.
System.err. Campo estático de salida de tipo PrintStream lo que permite escribir en elerror estándar.
A continuación se indican los métodos principales print y println de la clase PrintStream
Métodos print con parámetros distintos
void print(boolean b)
void print(char c)
void print(char[] s)
void print(double d)
void print(float f)
void print(int i)
void print(long l)
void print(Object obj)
void print(String s)
Métodos print con parámetros distintos
void println()
void println(boolean x)
void println(char x)
void println(char[] x)
void println(double x)
void println(float x)
void println(int x)
void println(long x)
void println(Object x)
void println(String x)
Ambos métodos son métodos sobrecargados de la clase PrintStream. A continuación se añade un ejemplo con código fuente para la entrada y salida estándar.
1.-Ejemplo KeyboardInput
import java.io.*;
public class KeyboardInput {
public static void main(String[] args) {
try (BufferedReader in = new BufferedReader(new InputStreamReader(System.in))) {
String s = "";
while (s != null) {
System.out.print("Type xyz to exit: ");
s = in.readLine().trim();
System.out.println("Read: " + s);
System.out.println("");
if (s.equals("xyz")) {
System.exit(0);
}
}
} catch (IOException e) {
System.out.println("Exception: " + e);
}
}
}
Persistencia
La persistencia consiste en el proceso de serialización (secuencia de bytes) y la deserialización (reconstrucción del objeto obteniendo una copia a partir de los bytes) de un objeto en Java.
Un objeto tiene capacidad de persistencia cuándo puede almacenarse en disco o mediante cualquier otro dispositivo de almacenamiento o enviado a otra máquina y mantener su estado actual correctamente.
Dentro de una aplicación Java, cualquier clase que quiera ser serializada debe implementar la interfaz java.io.Serializable, marcador utilizado para indicar que la clase puede ser serializada.
Puede producirse la excepción NotSerializableException cuándo un objeto no se puede serializar.
Los campos marcados con los modificadores static o transient no pueden ser serializados por lo que al deserializar un objeto dichos campos apuntaran a un valor nulo o cero al finalizar la reconstrucción del objeto. A continuación se añade un ejemplo con código fuente para obtener la persistencia de los datos de un estudiante. Se incluyen la definición del objeto Student, y las clases para la persistencia junto a la clase de ejecución.
package persistence;
import java.io.Serializable;
public class MyClass implements Serializable {
public int a = 0;
private String cad1 = "";
static int b = 0;
private transient String cad2 = "";
Student student = new Student();
public String getCad1() {
return cad1;
}
public void setCad1(String cad1) {
this.cad1 = cad1;
}
public String getCad2() {
return cad2;
}
public void setCad2(String cad2) {
this.cad2 = cad2;
}
}
3.- Ejemplo SerializeMyClass
package persistence;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class SerializeMyClass {
public static void main(String[] args) {
MyClass myclass = new MyClass();
myclass.a = 100;
myclass.b = 200;
myclass.setCad1("Hello World");
myclass.setCad2("Hello student");
try (ObjectOutputStream o = new ObjectOutputStream(new FileOutputStream("file1.ser"))) {
o.writeObject(myclass);
} catch (IOException e) {
System.out.println("Exception serializing file1.ser: " + e);
}
}
}
4.- Ejemplo Student
package persistence;
public class Student {
String name = "Darío";
int age = 3;
}
Recordatorio
Las clases BufferedReader y BufferedWriter aumentan la eficacia de las operaciones de entrada y salida. Estas clases permiten gestionar el búfer y escribir o leer línea por línea. A continuación se añade un ejemplo sencillo utilizando un BufferedReader para leer la cadena «xyz» y finalizar la ejecución.1.-Ejemplo utilizando BufferedReader
try (BufferedReader in = new BufferedReader(
new InputStreamReader(system.in)))) {
String s = "";
System.out.print("Type xyz to exit");
s = in.readline().trim();
System.out.print("Read "+s);
// ...
}
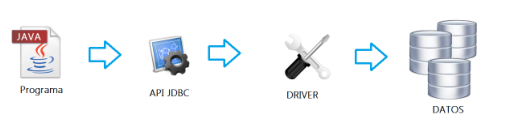
JDBC (Java Database Connectivity) es un acrónimo que identifica la API mediante la cuál las aplicaciones Java pueden conectarse a sistemas gestores de bases de datos (BBDD).
Esta conexión se obtiene por la utilización de interfícies de conexión llamadas controladores JDBC (o conocidos también como drivers).
Estas bases de datos acostumbran a ser en general relacionales, aunque también existen otros drivers para otros tipos de BBDD (nosql, ficheros planos, hojas de cálculo, etc).
API JDBC en Java 7 (Paquetes principales)
La API está compuesta por dos paquetes principales:
Ambos están ya incluidos dentro del SDK estándar de Java cuándo se descarga en su versión 7.
En las notas técnicas puede encontrarse información más detallada, este post pretende ser una introducción solamente.
Uso de JDBC
El paquete java.sql consiste en ejecutar sentencias SQL de tipo consulta, aunque también permite leer y escribir datos mediante operaciones de modificación realizando su conexión des de cualquier fuente de datos utilizando un formato tabular (en forma de tupla).
La URL del JDBC se construye mediante la plantilla siguiente:
jdbc : subprotocolo : subnombre
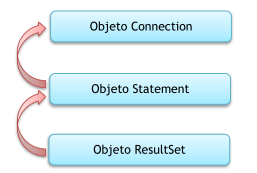
El esquema sobre la operación del controlador JDBC para ejecutar una sentencia SQL en Java:
El algoritmo de ejecución detallado en la imagen anterior es el siguiente:
1.-Mediante el DriverManager se utiliza el método getConnection(…) para disponer de una conexión al SGBD.
2.-Si se ha realizado la conexión con el SGBD de forma correcta, se crea la consulta mediante la API del JDBC utilizando el método createStatement(…).
Además en este paso se parametrizan los elementos que así lo requieran (valores adicionales en los elementos WHERE, posibles alias utilizados, etc)
3.-El último paso consiste en ejecutar la sentencia SQL y gestionar la tupla obtenida como resultado de su ejecución parametrizando la información según se requiera.
Por otro lado el paquete javax.sql, proporciona una API en la capa del servidor para el acceso a la fuente de datos y procesado del lenguaje de programación Java. Incorpora los siguientes añadidos:
La interfície de DataSource como una alternativa al DriverManager para establecer la conexión con una fuente de datos.
Pooling de conexiones y sentencias de SQL.
Transacciones distribuidas.
Conjuntos de filas.
Aplicaciones para utilizar directamente las API’s DataSource y RowSet, aunque las API’s del pooling de conexiones y de ls transacciones distribuidas se utilizan internamente por intermediarios.
Cuándo se cierran los recursos del JDBC una vez han sido utilizados se sigue el siguiente proceso:
Fig. 2. Cierre de la conexión
El cierre de Connection cierra automáticamente todos los recursos.
El cierre del objeto ResultSetdebe realizarse explícitamente siempre que no se utilice dado que si se deja automáticamente sólo se cerrará cuándo sea analizado por el recolector de basura. Es una buena práctica siempre cerrarlo explícitamente.
Por último siempre cerrar cualquier recurso externo que sea capaz de mantener activa la conexión del SGBD.
En Java 7 para cerrar correctamente todos los recursos JDBC debe utilizarse una herramienta introducida en llamada try-with-resources:
Esto permite cerrar todos los recursos al final del bloque de código.
Si se produce alguna excepción el bloque try antes de ser capturada la excepción, en el bloque catchse cierran los recursos en el orden inverso al utilizado.
Para utilizar correctamente la herramienta try-with-resources entre los paréntesis que lo implementan debemos utilizar los objetos que implementen la interfaz AutoCloseable.
Sql y JDBC
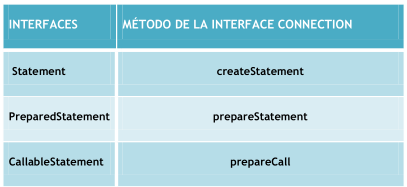
La API del JDBC:
No restringe las sentencias que se pueden utilizar en una BBDD.
No controla que las sentencias enviadas a la BBDD estén correctamente formuladas.
Suministra tres clases y tres métodos respectivamente para el envío de sentencias SQL:
Fig. 3. Creacion de objetos SQL
Statement: Utiliza el método de createStatement y incluye los métodos de executeQuery (para consultas) y executeUpdate(para operaciones de modificación).
PreparedStatement: Se utiliza para enviar consultas SQL que tengan uno o más parámetros como argumentos de entrada. Cuenta con métodos propios que nos ayudan a dar valor a estos parámetros. Se muestra el siguiente código fuente como ejemplo:
PreparedStatement ps = con.prepareStatement(
"select * from OWNER where ID=? AND NAME=? AND CODE=?");
ps.setInt(1,id-employee);
ps.setString(2,name);
ps.setInt(3,code);
CallableStatement: Se usan para ejecutar procedimientos almacenados SQL (Stored Procedures). Éstos son un grupo de sentencias SQL que son llamados mediante un nombre. Un objeto CallableStatement hereda de PreparedStatement los métodos para el manejo de parámetros y además añade métodos para el manejo de estos parámetros. Se muestra el siguiente código fuente como ejemplo:
Toda acción que se realice sobre la BBDD de datos abrir/cerrar conexión, ejecutar una sentencia SQL, etc pueden lanzar una excepción del tipo SQLException que se deberá capturar o propagar.
Este error puede resultar crítico para la integridad de los datos de la BBDD: la clase SQLException hereda de Iterablelo que permite recorrer dicha cadena de fallos. Así es posible recorrer todos los objetos de tipo Throwable que haya en una excepción SQLException.
Transacción
Mecanismo para manejar grupos de operaciones como si fueran una acción realizada de forma única.
Cada transacción debe tener las propiedades ACID:
Atomicidad (Atomicity). Una operación se hace o se deshace por completo.
Consistencia (Consistency). Transformación de un estado consistente a otro estado consistente.
Aislamiento (Isolation). Cada transacción se produce con independencia de otras transacciones que se produzcan al mismo tiempo.
Permanencia (Durability). Propiedad que hace que las transacciones realizadas sean definitivas.
Con JDBC se ejecuta un COMMIT automático (autoCOMMIT) tras cada insert, update o delete (con excepción de si se trata de un procedimiento almacenado).
Para indicar que una sentencia SQL no se ejecuta de forma automática se utilizará el método setAutommit(boolean); de la interfaz Connection pasándole como parámetro el valor false.
De este modo se pueden agrupar varias sentencias SQL en una misma transacción siendo el programador el que gestiona el momento de realizar el COMMIT de la ejecución.
ROLLBACK permite deshacer las transacciones que se hayan ejecutado dejando la BBDD en un estado consistente.
Si se cierra la conexión sin hacer COMMIT o ROLLBACK, explícitamente se ejecuta un COMMIT automático aunque el autoCOMMIT esté asignado a false.
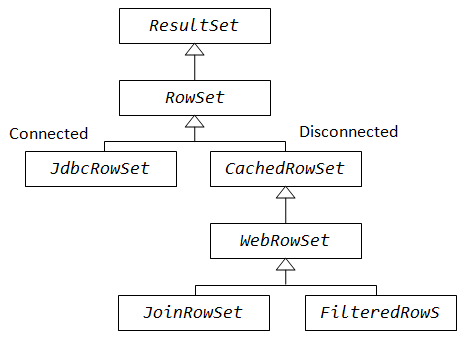
Api RowSet
Fig. 4. RowSet Api Description
Las interfaces que componen la API son las siguientes:
CachedRowSet
Permite obtener una conexión des de un DataSource, además de permitir la actualización y desplazamiento de datos sin necesidad de disponer de la conexión a BBDD abierta.
FilterRowSet
Deriva de RowSet y añade la posibilidad de aplicar criterios de filtros para hacer visible cierta porción de datos de un resultado global.
JdbcRowSet
Clase que engloba el funcionamiento básico de un ResultSet y añade capacidades de desplazamiento y actualización de datos.
JoinRowSet
Deriva de WebRoseSet y añade capacidades similares al JOIN de SQL pero sin necesidad de estar conectado a la fuente de datos.
WebRowSet
Deriva de CachedRowSet y añade funcionalidad para la lectura y escritura de documentos XML.
Las clases que componen la API son las siguientes:
BaseRowSet
Clase base abstracta que provee un objeto RowSet junto a su funcionalidad básica.
RowSetMetadaImpl
Clase que proporciona implementaciones para los métodos que establecen y recuperan información de los metadatos de las columnas del objecto RowSet.
Un objeto RowSetMetaDataImpl realiza un seguimiento del número de columnas del RowSet y mantiene un Array interno de los atributos de la columna para cada una de las columnas.
Un objeto RowSet crea internamente un objeto RowSetMetaDataImpl con el fin de establecer y recuperar información sobre sus columnas.
RowSetProvider
Se utiliza para crear un objeto RowSetFactory. A su vez, RowSetFactory se utiliza para crear instancias de implementaciones de RowSet (que deriva de ResultSet y por lo tanto contiene todas las capacidades de ResultSet pero añadiendo nuevas funcionalidades).
Representan errores producidos durante la ejecución de un programa por condiciones inválidas en el flujo esperado. Estos errores pueden ser previsibles o esperables y por eso se puede definir un flujo alternativo para tratarlos. Es el caso, por ejemplo, de errores de conexión de red, errores en la localización de ficheros, conexión a base de datos, etc. En estos casos, se puede aplicar una política de re-intentos o bien informar al usuario del error de forma controlada si se trata de un entorno interactivo.
Los métodos están obligados a tratar de alguna manera las excepciones de este tipo producidas en su implementación, ya sea relanzándolas, apilándolas o tratándolas mediante un bloque try/catch.
Exception y subclases, excepto RuntimeException y subclases.
Excepciones no comprobadas (unchecked).
Representan errores producidos durante la ejecución de un programa de los que no se espera una posible recuperación o no se pueden tratar. Se incluyen entre estos casos errores aritméticos, cómo divisiones entre cero, excepciones en el tratamiento de punteros, cómo el acceso a referencias nulas (NullPointerException) u errores en el tratamiento de índices, cómo por ejemplo el acceso a un índice incorrecto de un array.
Este tipo de errores pueden ocurrir en cualquier lugar de la aplicación y no se requiere su especificación en la firma de los métodos correspondientes o su tratamiento a través de bloques try/catch (aunque es posible hacerlo) lo que facilita a la legibilidad del código.
RuntimeException, Error y subclases de éstas.
En concreto la excepción no comprobadaError representa errores producidos por condiciones anormales en la ejecución de una aplicación que nunca deberían darse. En su mayoría se trata de errores no recuperables y por esta razón, este tipo de excepciones no extienden de Exception y si de Throwable con el propósito que no sean capturadas accidentalmente por ningún bloque try/catch que pueda impedir la finalización de la ejecución. A nivel de compilación, estos se tratan de igual forma que las excepciones no comprobadas, por lo que no hay la obligación de declarar su lanzamiento en las firmas de los métodos.
Ejemplos:
VirtualMachineError: Indica que se ha producido un error que impide a la máquina virtual seguir con la ejecución, sea porque se ha roto o porque no puede conseguir los recursos necesarios para hacerlo, cómo por ejemplo, por falta de memoria (OutOfMemoryError), porque se haya producido un desborde de la pila (StackOverflowError) o porque se haya producido un error interno (InternalError).
LinkageError: Indica incompatibilidades con una dependencia (clase) que ha sido modificada después de la compilación.
AssertionError: Indica un error en una aserción.
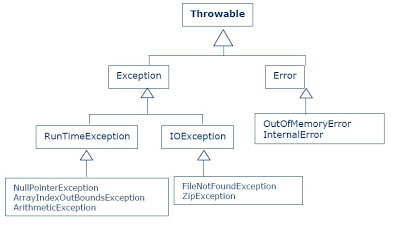
Jerarquía de Excepciones
La jerarquía de las excepciones en Java 7 puede visualizarse en el siguiente esquema:
Fig. 1. Jerarquía de excepciones
La superclase de todas las excepciones es Throwable.
La clase Exception sirve como superclase para crear excepciones de propósito específico, es decir, adaptado a nuestras necesidades.
La clase Error está relacionada con errores de compilación, del sistema o de la JVM. Normalmente estos errores son irrecuperables.
RuntimeException (Excepciones Implícitas): Excepciones muy frecuentes relacionadas con errores de programación. Existen pocas posibilidades también de recuperar situaciones anómalas de este tipo.
Lanzamiento de Excepciones
Para el lanzamiento de una excepción debe ejecutarse el siguiente código:
// Crear una excepcion
MyException me = new MyException("Myexception message");
// Lanzamiento de la excepción
throw me;
Bloque try-catch
El bloque que puede lanzar una excepción se coloca dentro de un bloque try. Se escribe un bloque catch para cada excepción que se quiera capturar. Ambos bloques se encuentran ligados en ejecución por lo que no debe existir una separación entre ellos formando una estructura try-catch conjunta e indivisible. Pueden asociarse varios bloques catch a un mismo bloque try.
import java.util.*;
public class ExTryCatch {
public static void main(String[] args){
int i=-3;
try{
String[] array = new String[i];
System.out.println("Message1");
}
catch(NegativeArraySizeException e){
System.out.println("Exception1");
}
catch(IllegalArgumentException e){
System.out.println("Exception2");
}
System.out.println("Message2");
}
}
Bloque Finally
Cuándo se agrupan excepciones al acceder a uno de los catch el resto de catch no se ejecutarán y puede provocar un error en la liberación de recursos utilizados en un programa. Java cuenta con un mecanismo para evitar esto de forma consistente en el bloque de código finally el cuál siempre se ejecuta.
import java.util.*;
public class ExFinally {
public static void main(String[] args){
int i=5;
try{
String[] array = new String[i];
}
catch(NegativeArraySizeException e){
System.out.println("Exception1");
}
catch(IllegalArgumentException e){
System.out.println("Exception2");
}
finally{
System.out.println("This always executes");
}
}
}